In today's article we are going to talk about how you can take advantage of Upstash to securely store and access information about a country's shelter map using Redis, and update the database in realtime via QStash.
Introduction
In the current global context, natural disasters and military threats are becoming more and more prevalent. So does the need for digitalisation in the social services area.
Ranging from emergency broadcast systems such as the AMBER alerts to COVID-19 tracking apps and the SOS systems, we have seen a wide range of technologies being used in response to any kind of dangerous scenario that affects a country.
Now, we are going to take a look at how Redis and serverless workloads can play a key role in building a realtime emergency response system that helps citizens find the closest bunkers, while also informing them about the capacity, features(such as disabled persons facilities) and resources(water, electricity, medicine etc.) available.
The so-called serverless concept has been popularised among developers for the last years. We have seen an increase in the number of startups that choose to follow this architecture and also an increased adoption in large corporations.
Especially when talking about state actors, a rapid development environment and auto-managed services can drastically reduce the complexity and overhead of building emergency response systems. We also have to take two other factors into consideration:
Budget: If a country does not go through an emerging disaster, will any person in a decision-making role be able to approve payments for unused compute power? I doubt so.
Traffic spikes: Imagine an alarm is triggered and millions of people access the web platform to find the closest shelter. How will your REST API handle this sudden rps(request-per-second) increase? What about the essential realtime components?
All this different questions can be answered by using true serverless platforms like Upstash and Ably to power up heavy-lifting servers that auto-scale and charge only for the resources you are using.
Why Redis?
Our project's data requirements include various algorithmic operations that must be performed at the highest possible speed. From basic data structures for representing a shelter's information to having a simple way to sort the ones available in a location by different criteria, Redis allows us to maintain the flexibility of a NoSQL database, while also providing various functions to simplify and accelerate development.
Why QStash?
Traditional message queues provide a solid way to architect event-driven systems, but there is a caveat: most of them fully depend on stateful protocols like AMPQ, meaning they are not ready to be used in short-running environments like serverless functions.
QStash solves this problem by allowing requests to be made using HTTP, the stateless protocol typically used in such environments. Combining that with webhooks, we can create realtime pipelines to update and fetch the data from and into the database.
Requirements
P.S.: If you just want to look through the samples, skip the requirements and setup section. They are meant to show what we are using and how.
If you would like to build this kind of system on your own, you will need the following:
an Upstash account, from which you will create a Redis database and use a QStash endpoint or topic;
a tunneling service like ngrok if you want to proxy local requests to an internet available URL;
any package manager that supports the requested libraries. This article will use npm, but it is not mandatory.
NOTE: This article will provide some basic proof-of-concept samples to demonstrate the use of said technologies in the context of our application's architecture. The given code is NOT production ready and was simplified and shortened for better reading. Make sure to perform the necessary modifications if you would like to deploy(exception handling, security, etc.)
Setup
Serverless functions
We are going to use Next.js's edge API routes to run serverless workloads closer to the user's location.
To create a Next.js project run npx create-next-app@latest <your-app-name> in the parent directory. After that you can run npm run dev to start the development server, npm run build to create a production bundle and npm run start to start the production server.
Next.js uses the node environment for API routes as a default. We can change that in two ways:
The per-route approach. Add the following export to the desired route:
To setup a QStash-receiver route, follow this guide.
Note that Ably provides us with two options for the webhook message encoding, JSON and MessagePack. If you want to use the former, you might need to use an authorization header instead of JWT to work along potential encryption compatibility problems. For simplicity we will stick to JSON.
Ably
For the realtime functionality, we will use Ably's protocols, that defaults to WebSockets where possible. To get started follow this guide and, as we are using Next.js, you can take a look at the @ably-labs/react-hooks npm package.
We should also set up a webhook integration to point to our QStash URL, and add any necessary headers.
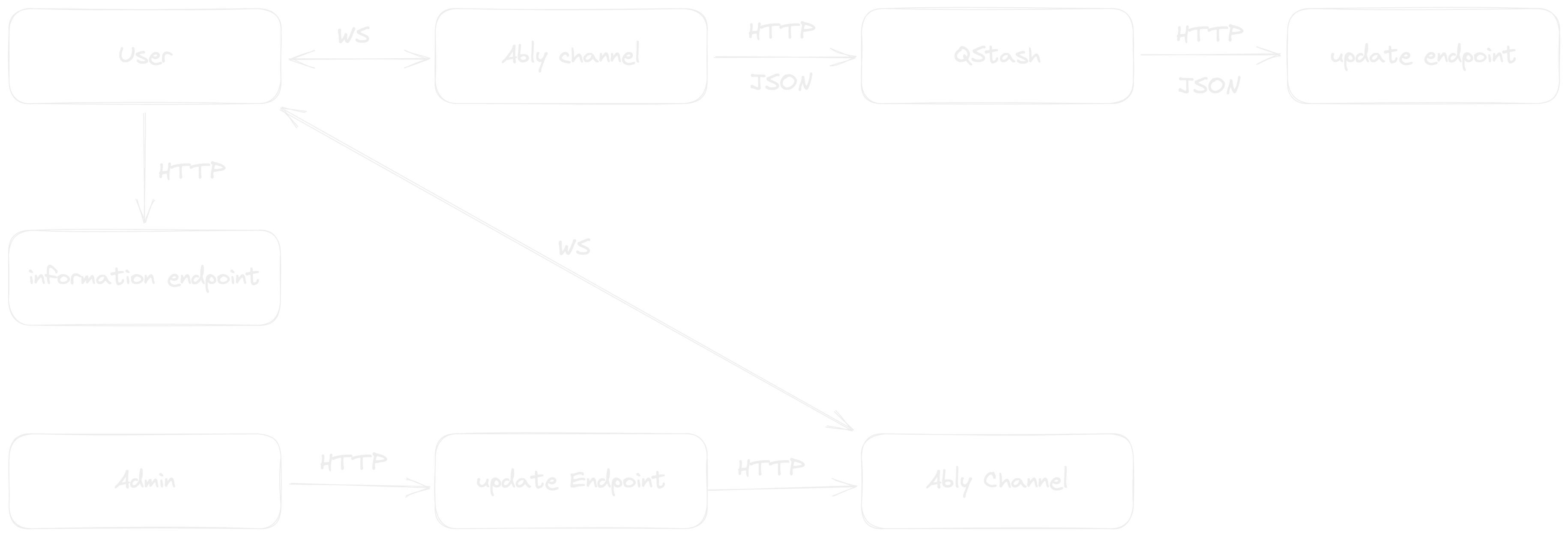
To better understand our application's flow, let's look at this diagram(created with excalidraw.com):
As you can see we have defined two types of users:
the citizen, who can acces a shelter or a location's info, and can announce his intention to go to a bunker
the admin, who can modify a bunker's logistics data and modify the availability(for example, confirm that a person/family arrived at the location)
We are trying to make the data available in realtime while maintaining the frontend and backend as decoupled as possible, so we will use an Ably channel to communicate with the client and trigger a webhook every time the availability changes.
Also, we will use Ably's REST API to publish messages from the backend, as we should not use any sort of stateful connection.
Data
Currently we have to store two main data types:
a shelter's information, which can take the form of a Redis hash and have the following properties:
the key's name as country-city-number (ex: RO-CJ-01)
availability (ex: 300)
features (ex: ["disabled persons special acces", "counseling"])
While we can do a nested query to find the shelters available for the specified location, it might be a better idea to store them as a separate data structure to simplify and optimise the query. To do so, we can use a Redis set and name the elements as <geographical-unit>-<name> (ex: country-RO or city-CJ). This way we are also preventing duplication
ex:
city-CJ : ["RO-CJ-01", "RO-CJ-02", "RO-CJ-03"]
But there still remains one problem: how can we distinguish between a citizen's intention to go to a shelter and an actual update of the occupancy triggered by the shelter's admin confirmation? We can do so in two ways:
Constantly update the shelter's availability key:
A user announces his intention to come (alone or with the family/etc) => we increment by x;
The admin finds out the confirmation is not valid => we decrement by x (or increment by -x)
The problem here is that the admin must act as a source of truth and keep track of citizen's location; also, the shelter's data can't be immediately trusted
Create a separate string key named shelter-"availability" (ex: RO-CJ-01-availability) and store the realtime-updated value.
This way we can update realtime, and keep our hash's availability key as the source of truth.
Note that on the client side we will fetch both the hash and the string key, and present them as the actual availability and the projected one. An alternative approach would be to only fetch the string and revert to the source of truth when needed. Although this would reduce the network load, the admin would need to constantly verify the data(as in the first scenario) and, to actually fetch less, we would need to store the shelter's availability key separately(remember, we still need to get the other informations!).
Sorting
Let's take advantage of another Redis data type called sorted set. Say we want to sort the bunkers in a location by availability, facilities or available resources: as I mentioned previously, we can do a nested query but at the cost of time and with a much bigger data load. A better solution would be to create sorted sets for every filtering criteria (we can name them <geographical-unit>-<name>-<criteria>, like city-CJ-availability or country-RO-food)
ex: city-B-availability
Score
Content
200
RO-B-02
100
RO-B-01
In this example, the availability score was calculated as total seats - current occupation.
Examples
We can write some basic code to demonstrate our API and client's behaviour
Endpoints
Mainly, we need to have:
a data endpoint that would serve the client any requested information
and
an edpoint to create or update our data types
Client
After tracking the user's location we will automatically connect to the "availability" channel and publish a message if the citizen intends to go to a bunker.
First, let's make a connection from the /_app.js file:
import { useEffect, useState } from "react";import "../styles/globals.css";import { configureAbly } from "@ably-labs/react-hooks";export default function App({ Component, pageProps }) { const [loaded, setLoaded] = useState(false); useEffect(() => { configureAbly({ // In a production system, you should use authentication key: process.env.NEXT_PUBLIC_ABLY_API_KEY, }); setLoaded(true); }, []); if (!loaded) return <div>loading...</div>; return <Component {...pageProps} />;}
And then connect to the channel in any component we need to:
To add new data to Redis we can use the HSET, SET and SADD commands
export default async (req) => { let data = await req.json(); if (data.type === "shelter") { // Remove the 'type' key as it is not neccesary anymore delete data.type; const { name: shelter, availability } = data; let shelterData = data; // Generate a random id. shelterData._id = Math.random() .toString(36) .replace(/[^a-z]+/g, "") .substring(0, 7); // Store the shelter's info as a hash await redis.hset(shelter, shelterData); // Store the realtime-updated availability as a string await redis.set(shelter + "-availability", availability); return new Response("ok"); } else if (data.type === "location") { const { name: location, shelters } = data; await redis.sadd(location, ...shelters); return new Response("ok"); }};
Updating existing data
Other than basic UD (update-delete) operations, we can use the Redis INCRBY and HINCRBY commands to modify the shelters's availability.
If a citizen announces his intention to go to a bunker, we can publish a message from the client app
availability.publish("update", { shelter: "RO-CJ-01", availability: 1, // Or -x, if the user cancels.});
As explained in the architecture, this will trigger a webhook from which we can take the data and update the shelter-"availability" key.
On the client, we can listen for messages in the channel and update the state accordingly.
To sum up
Today we took a look at how we can leverage a powerful serverless architecture to build a real-world emergency tracking app. While there are multiple approaches to get this done, I personally recommend going with this kind of flow because of the simplified developer experience.
Maybe you are a senior developer used to building distributed computing systems and feel the need for a managed service. Or, you may be a beginner but have an idea that can potentially change the world for good. Finding the right tools is always an essential part of the process.
Let me know what you think about this article, and if you have any question feel free to message me on LinkedIn or check my other codes on Github.

 Courtesy of Project Cloud4
Courtesy of Project Cloud4