
Introduction
In this tutorial, we will explore how to build a semantic search engine in Python with just a few lines of code. We will be using HuggingFace and
Upstash-Vector, a vector database for efficient and convenient similarity search.
Our final product will contain 10,000 posts from StackOverflow and will match user questions with relevant posts. This whole tutorial will take just a minute of execution time in Google Colab with a Nvidia T4 GPU.
All of the resources used in this project can be obtained for free.
Semantic Search Algorithm
To perform a semantic search we will use the all-MiniLM-L6-v2 model to convert strings to semantic embeddings. This model is trained so that semantically similar strings and question-answer pairs result in embeddings with high cosine similarity.
At first, our system will encode the entities in our database and insert them to Upstash-Vector with their corresponding embeddings. Afterwards, queries will be vectorized and the vector database will allow us to retrieve posts with similar embeddings easily. As the database uses the state-of-art DiskANN method for the nearest neighbor search, we will enjoy low latency insertion and retrieval.
Codebase
You can find the Jupyter notebook for this project here.
Getting Started
Initializing the Model
At first, we should select a model to convert strings to semantic embeddings as this process affects the database setup. For our demonstration, we will use all-MiniLM-L6-v2. This model provides a fast inference time and is suitable for a semantic search application as its training data contains actual query-result pairs from Yahoo and Stack Exchange.
all-MiniLM-L6-v2 is provided by the sentence-transformers package from HuggingFace. This package can be installed using pip.
pip install -U sentence-transformers
We can initialize this model in a Python script as in the following.
from sentence_transformers import SentenceTransformer
model_name = 'all-MiniLM-L6-v2'
encoder = SentenceTransformer(model_name)Downloading the Data
For our demonstration, we will use the first 10,000 entities of the stackoverflow-python dataset from the sentence-transformers package. The data contains titles and bodies of actual posts with the Python tag. This dataset can be downloaded using the utils module of the sentence_transformers package.
import os
import json
import gzip
from sentence_transformers import util
NUM_SAMPLES=10000
#downloading dataset
database_filepath = 'data/stackoverflow-python.jsonl.gz'
if not os.path.exists(database_filepath):
util.http_get('https://public.ukp.informatik.tu-darmstadt.de/reimers/sentence-transformers/datasets/stackoverflow-python.jsonl.gz', database_filepath)
#preparing title and body pairs
entities = []
with gzip.open(database_filepath, 'rt', encoding='utf8') as f_input:
for i, line in enumerate(f_input):
if i == NUM_SAMPLES:
break
data = json.loads(line.strip())
entities.append([data['title'], data['body']])
print("Number of entities:", len(entities))Preparing the Vector Database
Now that the data and a semantic encoder are ready, we should insert the data to the vector database for retrieval.
Creating the Vector Index
Firstly we will create an index using the Upstash console. During this stage, we should configure the index according to the model. As the encoder uses 384-dimensional embeddings, the vector index should be set for 384-size vectors. Similarly similarity metric should be set to cosine similarity as this metric is supported for the model.
You can find more about index creation here.
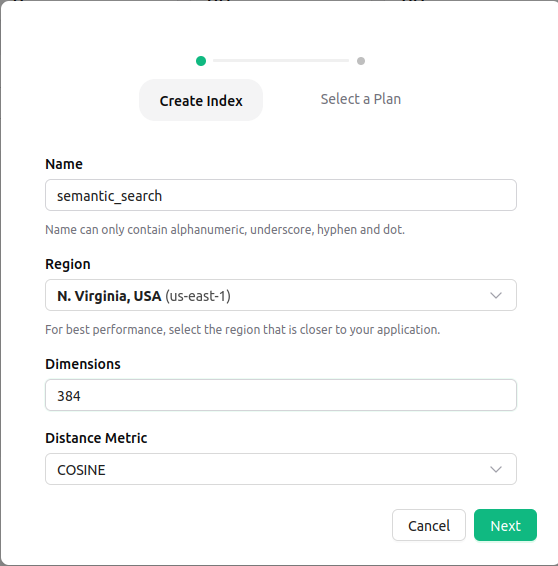
Connecting to the Vector Index
We will use Python-SDK to connect to the created index in our application. This SDK can be installed using pip as in the following:
pip install upstash_vector
Upon installing the SDK, we can connect the index as follows. You can copy the version of this snippet with your URL and token are inserted from the Connect section in the console.
from upstash_vector import Index
INDEX_URL="URL"
INDEX_TOKEN="TOKEN"
index = Index(url=INDEX_URL, token=INDEX_TOKEN)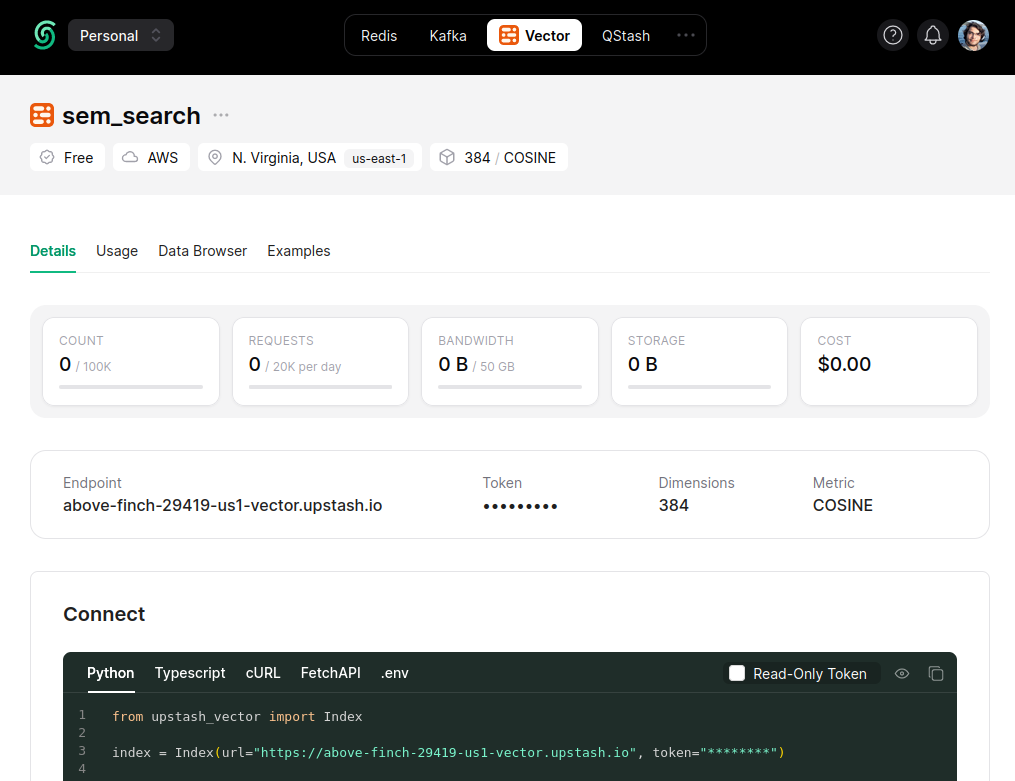
Populating the Vector Database
Now that the vector index is initialized and connected, we should add entries to perform a search.
Encoding the dataset
Let us begin with encoding entities from StackOverflow. This can be simply done using the model from sentence-transformers package.
entity_embeddings = encoder.encode(entities, convert_to_tensor=True, show_progress_bar=True, batch_size=256)Insertion to the Vector Index
As we get post-encoding pairs, we can start inserting them into the vector index. As we have 10,000 entities, we should use paging during insertion.
During insertion, each index entity consists of a list of size 3 in the following structure.
[UID, vector, {metadata}]In this list, uid is a unique identifier string. At each index, only one entry with the same UID can exist, and insertions to an existing UID result in an update operation. Vector is the vector corresponding to this entry and the metadata is a free dictionary we can use to store classic database fields such as title, body, or upvotes.
With these in mind, we can perform a bulk insert operation with the Index.upsert method. We will upsert our database as pages of 1000 entries. As shown in the following:
import time
#Insert dataset entities with 1000 size pages.
#Maximum page size is 1000.
PAGE_SIZE = 1000
end_cursor = -1
for start_cursor in range(0,len(entities),PAGE_SIZE ):
end_cursor = PAGE_SIZE + start_cursor
end_cursor = min(len(entities), end_cursor)
vector_chunk = [(f"entity_id-{j}", entity_embeddings[j].tolist(), {'body': entities[j]}) for j in range(start_cursor, end_cursor)]
start = time.time()
res = index.upsert(vectors=vector_chunk)
end = time.time()
print(f"Upsert latency: {round(end-start,2)}ms, res:{res}, range: {start_cursor}-{end_cursor-1}")Implementing the Semantic Search
Upon preparing our vector index, the only remaining step is to encode the query and retrieve posts with similar encodings. This is the point using a vector database is beneficial for our project. Using the query method of the index object, we can retrieve entities both by id and their vectors. Therefore, the search method has two steps, given a query string, encode the query the index for similar strings. This can be implemented as such:
NUM_RESULTS_PER_SEARCH = 3
def search_in_index(query):
#Encode the query using the encoder
question_embedding = encoder.encode(query, convert_to_tensor=True).tolist()
#Get the top 3 entities with the highest similarities.
response = index.query(vector=question_embedding, top_k=NUM_RESULTS_PER_SEARCH, include_metadata=True)
#Print the collected results
for i, result in enumerate(response):
print(f"\x1b[31mResult {i+1}, id: {result.id}, score:{result.score}:\n\x1b[0m")
for paragraph in result.metadata["body"]:
print(paragraph)
print("\n")Results
This section is reserved for some example queries and the returned results.
Please note that we only used 10,000 entities for our example which is far less than the number of topics available in Python. Therefore, some queries will yield non-related results as there are no corresponding posts.
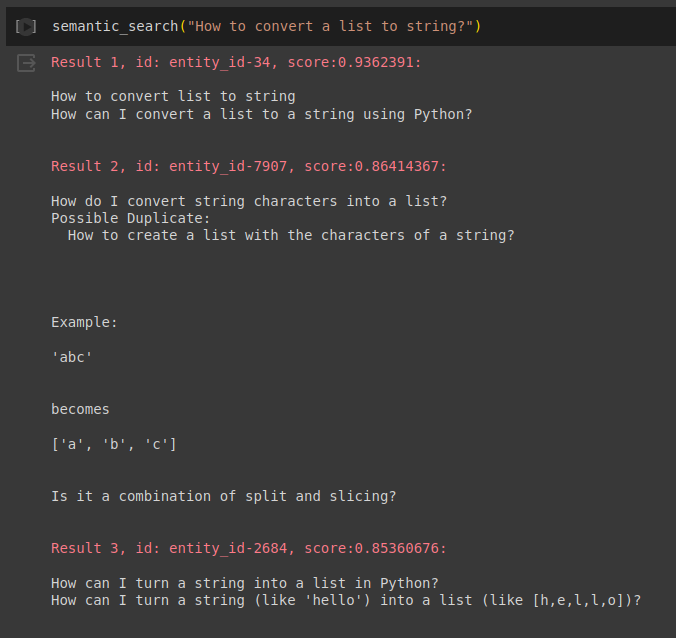
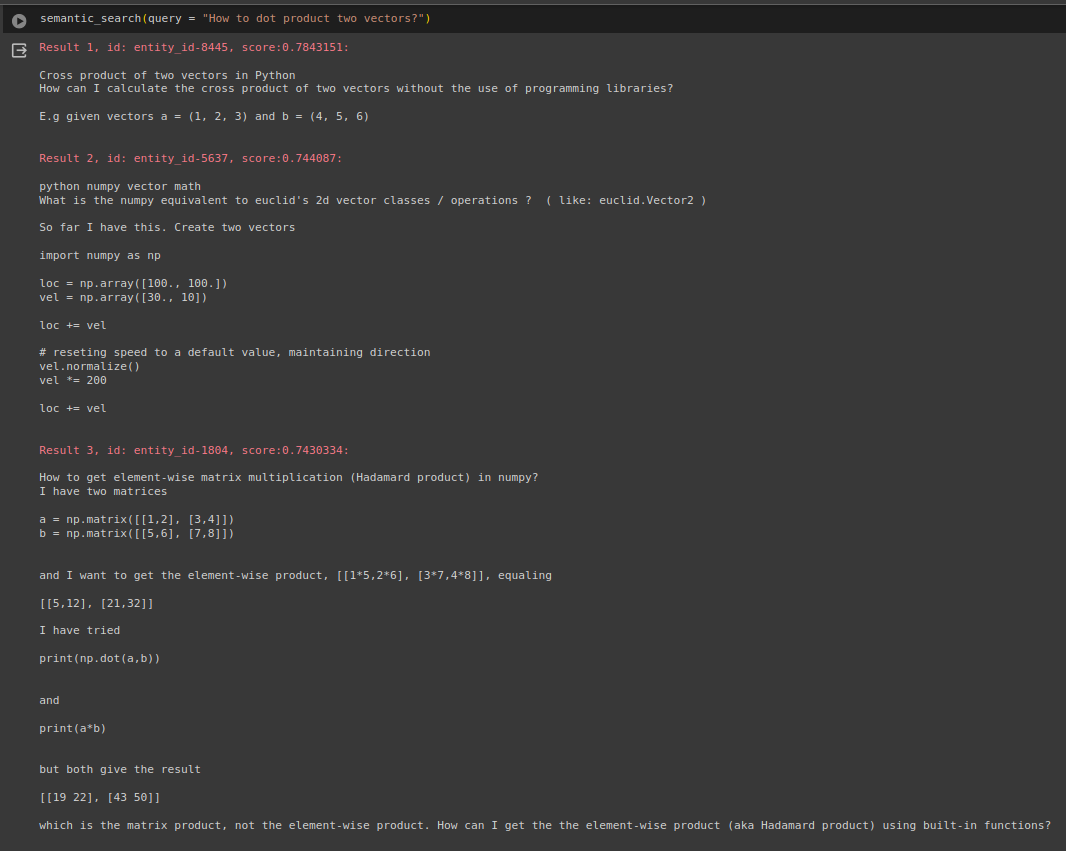
Conclusion
In this blog post, we demonstrated how a semantic search algorithm can be easily implemented using the Upstash-Vector.
If you enjoyed this tutorial, be sure to check out our other tutorials on the Upstash blog.
If you have any questions or comments, feel free to reach out to me on GitHub or LinkedIn.