Make Your Own Message Queue with Redis and TypeScript

Have you ever tried to create your own Message Queue but faced challenges? If so, you're not alone. In this tutorial, we're going to build a message queue from scratch using Redis lists. While there are several methods to construct message queues with Redis, such as streams, lists, and pub/subs, we'll focus on the simplest and most straightforward approach: lists. Join me as we delve into this practical guide.
What we’ll be using
- Upstash
- Pair of hands
What you'll need
- Bun
- Pair of hands
Setting up Upstash Redis
First, let's set up a Redis instance. To do this, simply go to Upstash and click on Create Database. After that, scroll down to find your connection string, which is what we'll use to connect our client. I won't go into the details here, but that's essentially what you need to get started.
Example connection string:
redis://XXXXe@social-XXX-39281.upstash.io:39281Project Kickoff
Let's start our TypeScript project using Bun. The choice isn't just because it's faster than Node—it's also much easier to set up. And yes, it's impressively fast too! 🚀
mkdir upstash-mq
cd upstash-mq
bun init
> package name (upstash-mq-tutorial): upstash-mq
> entry point (index.ts):
> Done!
bun add ioredisProject Structure
┣ 📂src
┃ ┣ 📂lua-scripts
┃ ┃ ┣ 📜add-job.lua
┃ ┃ ┗ 📜remove-job.lua
┃ ┣ 📜index.ts
┃ ┣ 📜job.ts
┃ ┣ 📜queue.ts
┃ ┗ 📜utils.ts
┣ 📜.env
┣ 📜.gitignore
┣ 📜README.md
┣ 📜bun.lockb
┣ 📜index.ts
┣ 📜package.json
┗ 📜tsconfig.jsonVisual representation of our Queue will be like:
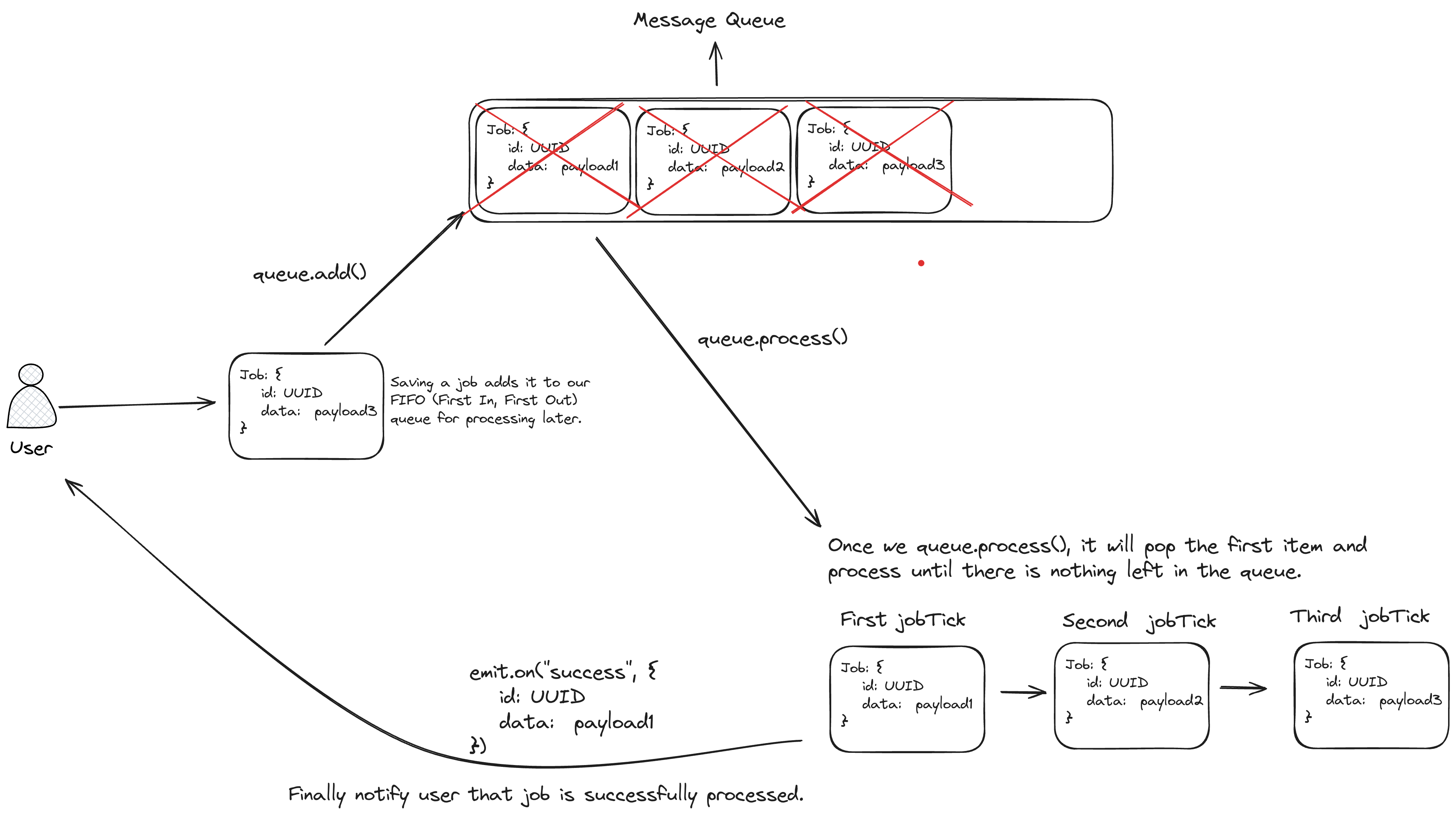
Job
Our Job class needs a few key things. First, we need to track the status of each job. This helps us decide whether to process them, try them again, or move them elsewhere if they're already finished. Each job also has an ID and some data, which needs to be generic so we can provide a great user experience. Lastly, we need to link each job to its queue and include the queue name for easy management.
Here are the backbones of our Job class:
type OwnerQueue = {
redis: Redis;
queueName: string;
};
export type JobStatuses =
| "created"
| "waiting"
| "active"
| "succeeded"
| "failed";
export class Job<T> {
id: string;
status: JobStatuses;
config: OwnerQueue;
data: T;
constructor(ownerConfig: OwnerQueue, data: T, jobId = randomUUID()) {
this.id = jobId;
this.status = "created";
this.data = data;
this.config = ownerConfig;
}
}To make the data generic, we need to first make the Job itself generic. The rest follows in a straightforward manner.
We could create a separate Redis instance for each Job element, but managing this would be complex.
Fortunately, our approach allows for easy configuration of the Redis instance within the queue, and we can simply pass this instance as needed. The same principle applies to queueName. Since we'll frequently use it to save jobs to queues, our jobs must be aware of their parent queues.
To be able to save jobs into queues, we need two things: a Lua script to interact with Redis and some utilities.
Let's create our utilities first:
import { JobStatuses } from "./job";
const MQ_PREFIX = "UpstashMQ";
export const formatMessageQueueKey = (queueName: string, key: string) => {
return `${MQ_PREFIX}:${queueName}:${key}`;
};
export const convertToJSONString = <T>(
data: T,
status: JobStatuses,
): string => {
return JSON.stringify({
data,
status,
});
};Since manually creating our queue name each time we use Redis isn't ideal, we've made a utility called formatMessageQueueKey.
This utility simply concatenates strings together. Additionally, we need to serialize our data to store in Redis - we can't just pass JS objects as a data source; they need to be converted into strings first.
Given that data is generic, we've implemented a generic function, convertToJSONString, for this purpose.
Now, let's add our first lua script:
add-job.lua
--[[
key 1 -> [prefix]:name:jobs
key 2 -> [prefix]:name:waiting
arg 1 -> job id
arg 2 -> job data
]]
local jobId = ARGV[1]
local payload = ARGV[2]
if redis.call("hexists", KEYS[1], jobId) == 1 then return nil end
redis.call("hset", KEYS[1], jobId, payload)
redis.call("lpush", KEYS[2], jobId)
return jobIdWe could perform these calls with our Redis instance individually, as follows:
redis.hexists(jobId)redis.hset(jobId,payload)redis.lpush(jobId,payload)
However, this approach would result in three separate calls. To minimize the round trips to the Redis server, we aim to consolidate the entire process into a single call.
Let's add our save() method
private createQueueKey(key: string) {
return formatMessageQueueKey(this.config.queueName, key);
}
async save(): Promise<string | null> {
const addJobToQueueScript = await Bun.file("./src/lua-scripts/add-job.lua").text();
const resJobId = (await this.config.redis.eval(
addJobToQueueScript,
2,
this.createQueueKey("jobs"),
this.createQueueKey("waiting"),
this.id,
convertToJSONString(this.data, this.status)
)) as string | null;
if (resJobId) {
this.id = resJobId;
return resJobId;
}
return null;
}The code is straightforward, but let me clarify further. After creating our Lua script, we call it using redis.eval, which is necessary for executing Lua scripts. The parameters for redis.eval are as follows:
- The first parameter requires the script.
- The second parameter specifies the number of arguments.
- The third and fourth parameters are for the keys.
- Lastly, we pass the actual arguments.
Before we finish our Job class let's add a couple more methods for future.
fromId = async <T>(jobId: string): Promise<Job<T> | null> => {
const jobData = await this.config.redis.hget(this.createQueueKey("jobs"), jobId);
if (jobData) {
return this.fromData<T>(jobId, jobData);
}
return null;
};
private fromData = <T>(jobId: string, stringifiedJobData: string): Job<T> => {
const parsedData = JSON.parse(stringifiedJobData) as Job<T>;
const job = new Job<T>(this.config, parsedData.data, jobId);
job.status = parsedData.status;
return job;
};Right now, we may not need these functions, but they will become crucial when we start processing jobs in the future. At that point, we'll only have the job's ID (jobId), and we will need a method to reconstruct our Jobs from scratch. This is precisely what fromId accomplishes. It retrieves the job data from Redis, converts it into a Job instance, and returns it, so the queue can later process this job.
Moving on to Queue
Having completed the save() part, let's dive into the details of Queue. Here are our objectives:
- We aim for our queue to either retain or remove data upon success or failure, as there may be cases where reprocessing is needed later.
- We intend to design the queue for concurrency, enabling multiple jobs to run simultaneously.
- Our goal is to allow the passing of a callback function for data processing. This function should infer the Job's type for a better developer experience.
- We plan to enable calling
Job.save()from within the Queue, allowing us to pass the Redis instance andqueueName. - Finally, we want to ensure the ability to destroy the queue if necessary and remove a Job from the queue.
Let's start with defining our Queue
export type QueueConfig = {
redis: Redis;
queueName: string;
keepOnSuccess?: boolean;
keepOnFailure?: boolean;
};
export class Queue extends EventEmitter {
config: QueueConfig;
concurrency = 0;
worker: any;
running = 0;
queued = 0;
constructor(config: QueueConfig) {
super();
this.config = {
redis: config.redis,
queueName: config.queueName,
keepOnFailure: config.keepOnFailure ?? true,
keepOnSuccess: config.keepOnSuccess ?? true,
};
}
createQueueKey(key: string) {
return formatMessageQueueKey(this.config.queueName, key);
}
}The Queue class includes a config to accept external information, such as the queue name, Redis instance, and settings for retaining or removing data. We welcome any Redis implementation that users prefer, although we have a special preference for Upstash 😌. This flexibility allows users to integrate the queue into their existing systems with ease.
And, our class extends Event Emitter to notify them when something happens.
Here is an example initialization:
const queue = new Queue({
redis: new Redis(process.env.UPSTASH_REDIS_URL),
queueName: "upstash-rocks",
keepOnFailure: true,
keepOnSuccess: true,
});Add
async add<T>(payload: T) {
return new Job<T>(this.config, payload).save();
}Our job takes the parent queue's configuration details and the payload, which is the data that will be stored in Redis. We then simply save it.
Now we can do that:
const queue = new Queue({
redis: new Redis(process.env.UPSTASH_REDIS_URL!),
queueName: "mytest-queue",
keepOnFailure: true,
keepOnSuccess: true,
});
const payload = {
upstash: "best-redis-ever",
};
await queue.add(payload);Now, we need a way to process them.
Processing
This is the most challenging part of our queue implementation. We require our users to specify the number of concurrent processes and provide a worker – a callback function to process jobs that will infer the job's type. Additionally, we need a mechanism to track the number of jobs currently running and queued, enabling us to safely select the next job from the queue.
async process<TJobPayload>(
worker: (job: TJobPayload) => void,
concurrency: number
): Promise<void> {
this.concurrency = concurrency;
this.worker = worker;
this.running = 0;
this.queued = 1;
this.jobTick();
}The primary purpose of accepting the generic TJobPayload is to enhance the developer experience for our users.
We aim to enable them to benefit from intellisense when using our queue.
Users are aware that they have stored data like {hello: "world"} in the Job, but TypeScript needs assistance to provide accurate intellisense.
This is why we have this mechanism in place, to inform TypeScript and force it to infer for better developer experience.
Before progressing to jobTick(), let's carefully consider the process:
- As our queue operates on a FIFO (First In First Out) basis, we need to start by popping a job from the right of the queue.
- Next, we run our worker function on this job.
- After the job is completed, we emit the result to our user.
- Finally, we call
jobTick()again to process the next job.
Therefore, jobTick() will be consist of these three critical parts."
private jobTick() {
this.getNextJob()
.then(async (jobId) => {
this.running += 1;
this.queued -= 1;
if (this.running + this.queued < this.concurrency) {
this.queued += 1;
setImmediate(this.jobTick);
}
if (!jobId) {
return;
}
const jobCreatedById = await new Job(this.config, null).fromId(jobId);
if (jobCreatedById) {
await this.executeJob(jobCreatedById);
} else {
console.error(`Job not found with ID: ${jobId}`);
}
})
.catch((error) => {
console.error("Error in jobTick:", error);
})
.finally(() => {
setImmediate(() => this.jobTick());
});
}I'll try to explain function by function. Let's start with getNextJob()
private async getNextJob() {
try {
const jobId = await this.config.redis.brpoplpush(
this.createQueueKey("waiting"),
this.createQueueKey("active"),
0
);
return jobId;
} catch (error) {
console.error("Error fetching the next job:", error);
throw error;
}
}
We're simply making a call to Redis, but with a strategic approach: we use a blocking call combined with lpush to minimize the number of round trips. The use of a blocking call is intentional; we want to prevent other workers from processing the same job simultaneously, thus avoiding race conditions. Additionally, we move jobs from the 'waiting' state to 'active', effectively preparing them for the next steps in the process.
this.getNextJob().then(async (jobId) => {
this.running += 1;
this.queued -= 1;
if (this.running + this.queued < this.concurrency) {
this.queued += 1;
setImmediate(this.jobTick);
}
if (!jobId) {
return;
}
const jobCreatedById = await new Job(this.config, null).fromId(jobId);
if (jobCreatedById) {
await this.executeJob(jobCreatedById);
} else {
console.error(`Job not found with ID: ${jobId}`);
}
});Now that we have the jobId, we increase the count of running jobs by one and decrease the queued count by one.
We also try to initiate as many new jobs as possible while respecting the concurrency limit:
if (this.running + this.queued < this.concurrency) {
this.queued += 1;
setImmediate(this.jobTick);
}If all goes well, we proceed to construct our Job using fromId.
Once we successfully reconstruct our job by its ID, we then move on to executing the job with our worker function.
Let's move on to executeJob
private async executeJob<TJobPayload>(jobCreatedById: Job<TJobPayload>) {
let hasError = false;
try {
await this.worker(jobCreatedById.data);
this.running -= 1;
this.queued += 1;
} catch (error) {
hasError = true;
} finally {
const [jobStatus, job] = await this.finishJob<TJobPayload>(jobCreatedById, hasError);
this.emit(jobStatus, job.id);
return;
}
}Now that we have the Job's data, we pass this data to our worker. If it executes successfully, we increase the count of queued jobs by one and decrease the running count by one. This step is crucial; if not handled correctly, it could impact our ability to launch new Jobs concurrently. In case of an error during the worker's execution, we simply switch the hasError flag. Finally, we call finishJob with our jobCreatedById and the hasError flag and emit the status with jobId.
Side note: Users can now listen for emitted updates like this.
queue.on("succeeded", (jobId) => console.log("Succeeded jobId", jobId));Let's move on to finishJob
private async finishJob<TJobPayload>(
job: Job<TJobPayload>,
hasFailed?: boolean
): Promise<[JobStatuses, Job<TJobPayload>]> {
const multi = this.config.redis.multi();
multi.lrem(this.createQueueKey("active"), 0, job.id);
if (hasFailed) {
if (this.config.keepOnFailure) {
multi.hset(this.createQueueKey("jobs"), job.id, convertToJSONString(job.data, job.status));
multi.sadd(this.createQueueKey("failed"), job.id);
} else {
multi.hdel(this.createQueueKey("jobs"), job.id);
}
job.status = "failed";
} else {
if (this.config.keepOnSuccess) {
multi.hset(this.createQueueKey("jobs"), job.id, convertToJSONString(job.data, job.status));
multi.sadd(this.createQueueKey("succeeded"), job.id);
} else {
multi.hdel(this.createQueueKey("jobs"), job.id);
}
job.status = "succeeded";
}
await multi.exec();
return [job.status, job];
}A crucial aspect here is the use of multi() since our aim is always to minimize round trips.
By using multi, Redis defers execution until we call exec().
If the user has set keepOnFailure and keepOnSuccess to preserve data, we will create two sets: one with the job's data and another with a list of job IDs for accessing this data. This approach applies to both success and failure scenarios. Naturally, we adjust the job's status accordingly. Finally, we execute the multi command with exec and return the job's status and the job itself for event emission purposes.
Finally, we have two remaining methods, which I won't detail extensively, as they utilize concepts we're already familiar with.
async removeJob(jobId: string) {
const addJobToQueueScript = await Bun.file("./src/lua-scripts/remove-job.lua").text();
return await this.config.redis.eval(
addJobToQueueScript,
5,
this.createQueueKey("succeeded"),
this.createQueueKey("failed"),
this.createQueueKey("waiting"),
this.createQueueKey("active"),
this.createQueueKey("jobs"),
jobId
);
}
async destroy() {
const args = ["id", "jobs", "waiting", "active", "succeeded", "failed"].map((key) =>
this.createQueueKey(key)
);
const res = await this.config.redis.del(...args);
return res;
}remove-job.lua
--[[
key 1 -> [prefix]:test:succeeded
key 2 -> [prefix]:test:failed
key 3 -> [prefix]:test:waiting
key 4 -> [prefix]:test:active
key 5 -> [prefix]:test:jobs
arg 1 -> jobId
]]
local jobId = ARGV[1]
if (redis.call("sismember", KEYS[1], jobId) + redis.call("sismember", KEYS[2], jobId)) == 0 then
redis.call("lrem", KEYS[3], 0, jobId)
redis.call("lrem", KEYS[4], 0, jobId)
end
redis.call("srem", KEYS[1], jobId)
redis.call("srem", KEYS[2], jobId)
redis.call("hdel", KEYS[5], jobId)
destroy() is to completely wipe the entire queue, and the other is to delete a specific job from the queue.
Let's see everything in action
import { sleep } from "bun";
import Redis from "ioredis";
import { Queue } from "./queue";
type Payload = {
id: number;
data: string;
};
const queue = new Queue({
redis: new Redis(process.env.UPSTASH_REDIS_URL),
queueName: "mytest-queue",
});
async function main() {
await generateQueueItems(queue, 20);
console.log("Sleep starting for 5 sec");
await sleep(5000);
queue.on("succeeded", (jobId) => console.log("Succeeded jobId", jobId));
await queue.process<Payload>((job) => {
console.log("Processing job:", job.data);
sleep(1000);
}, 3);
}
main();
async function generateQueueItems(queue: Queue, itemCount: number) {
for (let i = 0; i < itemCount; i++) {
const payload = {
id: i,
data: `dummy-data-${i}`,
// Add more properties as needed for your testing
};
const jobId = await queue.add(payload);
console.log(`Added item ${i} with jobId: ${jobId}`);
}
}Bonus Challenges
- Implement retry logic with exponential backoffs for both Redis access and worker processes.
- Develop an 'at least once' guarantee mechanism.
- Try to execute workers in Service Workers for better performance
- Add scheduled jobs
Wrap up
The best way to learn something is by building it, and an even better approach is to do so using Upstash Redis. Keep rocking.