
The data collected from users in real-time is very essential for improving the product, reacting on time, and growing much faster. For collecting, preparing, and storing data, we can use the serverless Kafka with one of the most common open-source streaming tools, which is Spark Streaming.
In this blog post, we will use Serverless Kafka to collect logs from a mobile application developed using React Native and send these logs to Apache Spark for streaming into the Cassandra Database.
A Simple Data Pipeline
Building data pipelines is a commonly used way for collecting, preparing, and storing the data to get insights into the running product.
In general, a data pipeline has three fundamental elements. These are source, processing steps, and destination.
Source can be any data producer such as a mobile app, a web application, etc. In our case, the source will be our mobile application, which is already developed in the previous blog post “Send React Native Logs to Serverless Kafka”.
Processing steps are serverless Kafka and Apache Spark for collecting and streaming logs.
In this scenario, our destination will be the Cassandra database. However, the destination can be anything such as a monitoring tool, or any data warehouse.
In summary, we will develop a simple data pipeline, which consists of serverless Kafka, Apache Spark, and Cassandra. The steps of the flow will be as following:
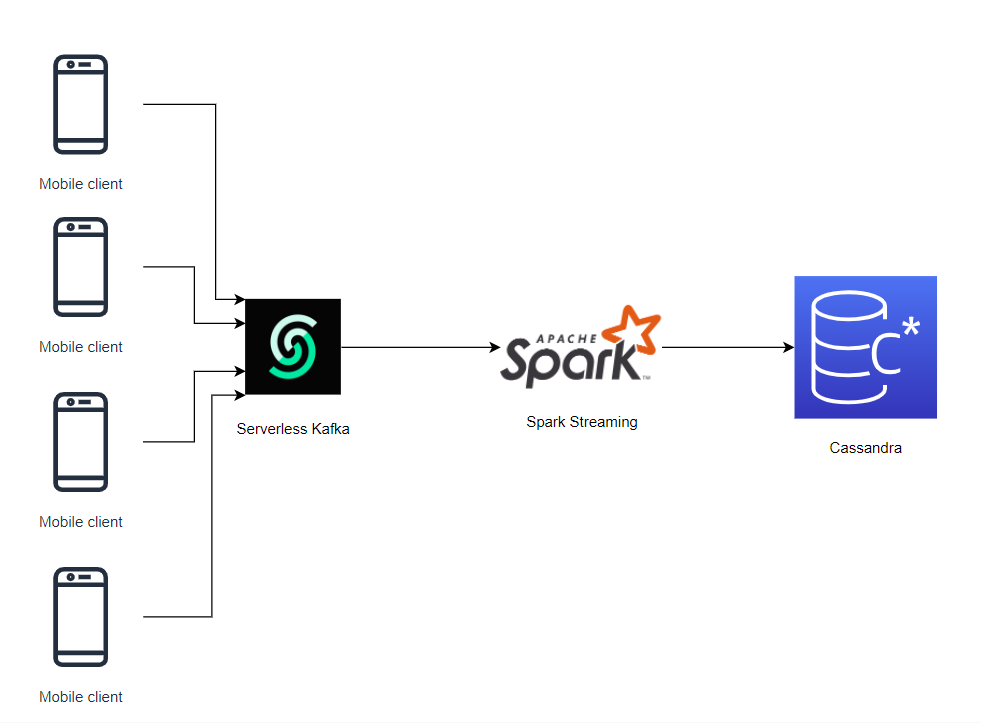
-
Producing logs from mobile clients
-
Collecting by serverless Kafka
-
Real-time streaming from Kafka to Cassandra with Apache Spark
-
Storing the data in Cassandra
From React Native App to Serverless Kafka
We will start with our source of data, which is the logs from the mobile app.
Installation and configuration steps can be followed from the previous blog, where the app and serverless Kafka are described.
A quick recap of the mobile app and its relationship with serverless Kafka:
In this mobile app, there is only one screen to keep the demo project simple. On this screen, there are four images of four different products on sale.

The prices of these products were stored in Upstash Redis. When a user clicks on these products, the mobile app reads its price from Redis, displays it on screen and produces a template log of this action to serverless Kafka. The topic of this event is “users.purchase”.
If an error occurs, then the application sends the error message to another Kafka topic “users.error”.
The following code block does the operations described above.
async costQuery(code){
console.log("CODE OF QUERIED PRODUCT: ", code);
await fetch('https://us1-maximum-boar-36431.upstash.io/get/' + code, {
headers: {
Authorization: "Bearer UPSTASH-REDIS-READONLY-TOKEN"
}
})
.then(response => response.json())
.then(async (data) => {
var result = data["result"];
if(result == null){
throw new Error("Price of the " + code + " could not found.")
}
else{
const res = await p.produce("users.purchase", "Cost of " + code + " is retreived successfully.");
Alert.alert("The price of the product is " + result);
}
})
.catch(async (err) => {
const res = await p.produce("users.error", err.message);
});
}For more detailed explanation of the mobile app and its interaction with serverless Kafka and Redis, please read the blog.
Configuring Cassandra
Streamed data must arrive at an endpoint according to the use cases of the data. This endpoint may be a dashboard, a file, a database etc.
In our case, we will save the data collected from users with Kafka and streamed with Spark into our Cassandra database.
Cassandra is a distributed NoSQL database, which provides high availability, high performance, and scalability for a very large amount of data. For more detailed information and installation procedure, please see its documentation.
In our demo project, we are going to design our database just for storing the log messages that come from serverless Kafka topics, users.purchase and users.error. Therefore, we are going to create a keyspace called “app” and create two tables for these two topics. Our tables will be “purchases” and “errors”.
In these two tables, there will be two columns: “message” and “time”. The log messages that will be streamed are going to be saved into “message” column and its timestamp will be saved into the “time” column. To keep the demo simple, we are going to work with just this information.
First, let’s create a keyspace in our database. We are going to use CQL “Cassandra Query Language” for doing operations on the database. Here is the documentation of it.
CREATE KEYSPACE app WITH replication =
{'class': 'SimpleStrategy',
'replication_factor': '1'
} AND durable_writes = true;
After that, we are going to create our tables as it is stated above.
CREATE TABLE app.purchases (message text, time timestamp, PRIMARY KEY (time));
CREATE TABLE app.errors (message text, time timestamp, PRIMARY KEY (time));
Now, our tables, which are going to be filled with the log messages streamed from serverless Kafka are ready.
cqlsh> SELECT * FROM app.purchases;
time | message
------+---------
(0 rows)
cqlsh> SELECT * FROM app.errors;
time | message
------+---------
(0 rows)
For more detailed and complex configuration, please check documentation.
Streaming From Serverless Kafka to Cassandra with Spark
Apache Spark is an open-source, distributed processing tool used for big data workloads and pipelining. Check out the Spark.
In this section, we are going to stream the data from serverless Kafka to Cassandra in two different ways: Structured Spark Streaming and Spark DStream, which is more legacy one. We will implement both ways in Java.
Firstly, we need to create a maven project and add the dependencies below to pom.xml file to work with Spark in Java.
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-kafka-0-10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.datastax.spark/spark-cassandra-connector -->
<dependency>
<groupId>com.datastax.spark</groupId>
<artifactId>spark-cassandra-connector_2.11</artifactId>
<version>2.5.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql-kafka-0-10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.11</artifactId>
<version>2.4.8</version>
</dependency>
</dependencies>While adding these dependencies, be sure that all Spark related dependencies have the same version on their artifactId to prevent any possible error which may occur. In our case, the version is 2.11.
- Spark Streaming
Streaming with DStream API receives data in mini-batches and performs operations over the data by separating them into chunks.
The first step of implementing a demo Spark streaming is configuring the Spark and creating a streaming context.
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local");
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
sparkConf.setAppName("ReactNativeKafkaSparkStreaming");
JavaStreamingContext streamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(1));Then, we need to configure our serverless Kafka connection. For this purpose, we are going to create props map as it is stated in Kafka API.
Map<String, Object> props = new HashMap<>();
props.put("bootstrap.servers", "hot-teal-10548-us1-kafka.upstash.io:9092");
props.put("sasl.mechanism", "SCRAM-SHA-256");
props.put("security.protocol", "SASL_SSL");
props.put("sasl.jaas.config", "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"UPSTASH-KAFKA-USERNAME\" password=\"UPSTASH-KAFKA-PASSWORD\";");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("auto.offset.reset", "earliest");Next, we can define topics that we are going to subscribe.
Collection<String> topics = Arrays.asList("users.purchase", "users.error");To collect data from Kafka to Spark Streaming, we can use KafkaUtils, which is a part of “spark-streaming-kafka” dependency as below.
JavaInputDStream<ConsumerRecord<String, String>> stream =
KafkaUtils.createDirectStream(
streamingContext,
LocationStrategies.PreferConsistent(),
ConsumerStrategies.<String, String>Subscribe(topics, props)
);At first, I have created a very simple “Message” class, which will be parsed and saved to the Cassandra. It contains the message and the timestamp as fields.
public class Message {
private String message;
private long time;
public Message(String message, long time) {
this.message = message;
this.time = time;
}
}In Spark Streaming, RDDs (Resilient Distributed Datasets), which are the main abstraction for Spark Streaming, are used to process the streamed data. According to the Spark Guide, RDDs are “collections of elements partitioned across the nodes of the cluster that can be operated on in parallel”. This abstraction provides fast, parallelized and fault tolerant processing system.
JavaPairDStream<String, String> data = stream.mapToPair(record -> new Tuple2<>(record.topic(), record.value()));
data.foreachRDD(javaRDD -> {
List<Tuple2<String, String>> dataMap = javaRDD.collect();
for (Tuple2 msgTuple : dataMap){
String msg = msgTuple._2.toString();
System.out.println("DEBUG MESSAGE: " + msg);
System.out.println("DEBUG TOPIC: " + msgTuple._1);
long time = System.currentTimeMillis();
List<Message> msgList = Arrays.asList(new Message(msg,time));
JavaRDD<Message> rdd = streamingContext.sparkContext().parallelize(msgList);
if("users.purchase".equals(msgTuple._1.toString())){
javaFunctions(rdd).writerBuilder("app", "purchases", mapToRow(Message.class)).saveToCassandra();
}
else{
javaFunctions(rdd).writerBuilder("app", "errors", mapToRow(Message.class)).saveToCassandra();
}
}
});Since we are going to save the log message and its timestamp, we retrieve the timestamp the data is received and the message that comes from the stream. To save these two elements, we use the following line and the “saveToCassandra” function for each RDDs. These messages are saved to corresponding table on Cassandra according to their topics.
javaFunctions(rdd).writerBuilder("app", "purchases", mapToRow(Message.class)).saveToCassandra();
javaFunctions(rdd).writerBuilder("app", "errors", mapToRow(Message.class)).saveToCassandra();At the end, we need to start and run the stream until the program terminated.
streamingContext.start();
streamingContext.awaitTermination();- Structured Streaming
Structured streaming is a newer approach compared to Spark streaming. It is better designed and optimized. It does not focus on batch processing as Spark streaming does. It processes the data and print or save it according to the choice of the user, such as “complete”, “append” or “update”.
At first, we need to create our Spark session.
SparkSession spark = SparkSession.builder()
.appName("ReactNativeKafkaSparkStreaming")
.config("spark.master", "local")
.getOrCreate();As the next step, we need to configure our stream, which returns Dataset object, by entering our Kafka props, dataset details and choices.
Dataset<Row> df = spark
.readStream()
.format("kafka")
.option("kafka.bootstrap.servers", "hot-teal-10548-us1-kafka.upstash.io:9092")
.option("kafka.sasl.mechanism", "SCRAM-SHA-256")
.option("kafka.security.protocol", "SASL_SSL")
.option("kafka.sasl.jaas.config", "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"UPSTASH-KAFKA-USERNAME\" password=\"UPSTASH-KAFKA-PASSWORD\";")
.option("startingOffsets", "earliest")
.option("subscribe", "users.error")
.load()
.selectExpr("CAST(value AS STRING)", "CAST(timestamp AS TIMESTAMP)")
.withColumnRenamed("value", "message")
.withColumnRenamed("timestamp", "time");The important point in configuring Kafka parameters in this example is adding “kafka” prefix to the keys, as it can be seen above code section.
In addition, the dataset columns should be same with the columns of Cassandra tables to stream data without any mismatches.
Now, we need to start stream to Cassandra. This stream should be formatted as “org.apache.spark.sql.cassandra”, which is provided with spark-cassandra-connector dependency. After that, we need to set the keyspace and the table, which will be filled, as options.
StreamingQuery query = df.writeStream()
.outputMode("append")
.option("checkpointLocation", "/tmp/check_point/")
.format("org.apache.spark.sql.cassandra")
.option("keyspace", "app")
.option("table", "errors")
.start();Again, we can set the stream as terminated when the program terminated.
query.awaitTermination();Everything is ready now. When we click on any images, the log is collected by serverless Kafka. Spark streams this log from Kafka and save it with its timestamp to the corresponding Cassandra table as below.
cqlsh> SELECT * FROM app.purchases;
time | message
---------------------------------+-----------------------------------------
2022-05-22 11:42:12.122000+0000 | Cost of 1234 is retreived successfully.
2022-05-22 11:42:21.263000+0000 | Cost of 1235 is retreived successfully.
(2 rows)
cqlsh> SELECT * FROM app.errors;
time | message
---------------------------------+-----------------------------------------
2022-05-23 15:19:09.025000+0000 | An error occured (Structured Streaming)
2022-05-23 15:17:47.249000+0000 | An error occured (Legacy Streaming)
(2 rows)
Conclusion
Data pipelines are built for performing the following processes over data: collecting, processing, and streaming to an endpoint.
In this blog post, we have implemented a simple pipeline by using serverless Kafka from Upstash to collect the data from the mobile application, Apache Spark to stream the data from serverless Kafka to our Cassandra database. At the end, we have used Cassandra as our database.
I hope this post helps you all!