Indexing Millions of Wikipedia Articles With Upstash Vector

Upstash offers a vector database that enables scalable similarity searches across millions of vectors, complete with features such as namespaces, metadata filtering, and built-in embedding models.
We continuously enhance our services with new features and a seamless user experience, striving to make them scalable to accommodate as many use cases as possible.
We have been rigorously stress-testing Upstash Vector, and recently indexed over 150 million vectors within a single namespace using synthetic embedding data. While we were pleased with the indexing and query performance of this large index, demonstrating these results to the public proved challenging. Despite the strong query performance and high recall, the synthetic nature of the data made it difficult to interpret the results.
Then, we decided to index a large volume of interesting text data and make it publicly accessible to everyone.
We chose Wikipedia as our data source for this project due to its vast repository of information on a wide range of subjects, and the ease of obtaining a copy directly from the source.
In this post, we'll walk you through how we created a semantic search engine and RAG chat bot using Wikipedia data that demonstrates the capabilities of Upstash Vector and RAG Chat SDK.
You can explore our project here.
Preparing the Embeddings
Upstash Vector operates in two modes. In the first mode, you provide the vector embeddings, and it manages the storage and retrieval of these vectors. In the second mode, you create an index with an embedding model and provide the textual data for insert and query operations; Upstash Vector then converts the text into vector embeddings using the model you've selected.
For this project, we had two possible approaches. There are several high-quality embeddings for the Wikipedia dataset from various providers, which we could have used with the first option described above. However, if we had taken this route, we would have needed to embed the query texts using the same models that were used to embed the Wikipedia data in order to achieve a functional semantic search engine and RAG chat.
Since we wanted to showcase the capabilities of Upstash Vector to the public, we decided to proceed with the second option and use the embedding models provided by Upstash for queries. With this decision made, we moved on to preparing the index.
Wikipedia includes texts in various languages. While most of the embedding models provided by Upstash work with English text, the BGE-M3 model is multilingual and performs well with different granularities of text, from short sentences to long paragraphs. Given these capabilities, it was the natural choice for this project, so we created our index using this model.
Wikipedia provides a complete copy of its source once or twice a month in the form of a wikitext dump. This data is publicly available, so we downloaded a recent version of the dump from June 1, 2024.
We decided to select the eleven most popular languages from the dump: English, German, French, Russian, Spanish, Italian, Chinese, Japanese, Portuguese, Persian, and Turkish.
Although the BGE-M3 model we chose for our index can handle relatively long texts, it requires a significant amount of GPU memory for embedding them. Additionally, as the length of the text increases, the quality of the queries may degrade because the model struggles to capture and express detailed information within its 1024-dimensional vectors.
To simplify the task for the model, we decided to split the dump and embed paragraphs instead of entire articles or large chunks of text. We observed that short paragraphs had low information density and did not yield useful query results. Therefore, we set a 100-character limit for paragraphs, omitting any paragraphs shorter than this from the dataset. Additionally, some paragraphs described the subject of the article without mentioning the subject's name, making it challenging to locate those paragraphs through queries. To address this, we decided to embed the article title along with each paragraph.
The text in the Wikipedia dump is in the form of Wikitext, a markup language. We couldn’t feed this text directly into the embedding model, so we first needed to parse and clean it. To accomplish this, we used a Python package called mwparserfromhell and referenced a script provided by Wikimedia to help with cleaning and splitting the data.
After preparing the data, we began the embedding process. We used SentenceTransformers and set up a separate machine for each language. Since English had the most paragraphs, we utilized a machine with an Nvidia A100 GPU for it, while the other languages were processed using machines with Nvidia L4 GPUs. The embedding process itself took nearly a week to complete.
In the end, we generated approximately 144 million vectors.
| Language | Article Count | Paragraph Count |
| English | 6.5 million | 47 million |
| German | 3 million | 20 million |
| French | 2.6 million | 18 million |
| Russian | 2 million | 14 million |
| Spanish | 1.9 million | 13 million |
| Italian | 1.9 million | 10 million |
| Chinese | 1.4 million | 3.3 million |
| Japanese | 1.4 million | 7.8 million |
| Portuguese | 1.2 million | 5.9 million |
| Persian | 1 million | 2.6 million |
| Turkish | 0.5 million | 2.1 million |
We plan to make the dataset public on Hugging Face, so you can benefit from it too. Keep an eye on the dataset page to access it once it's available.
Indexing the Vectors
For indexing the vectors, we chose to use multiple namespaces within a single index, with one namespace per language.
While generating embeddings, we configured SentenceTransformers to output embeddings in a normalized form. This allowed us to use dot product similarity for indexing.
The actual indexing process was relatively quick compared to the embedding. We uploaded all the vectors with some accompanying metadata, and Upstash Vector indexed them within a span of a few minutes to a few hours per namespace, depending on the number of vectors.
Building the Wikipedia Semantic Search
While uploading the vectors, we also included two pieces of information for each paragraph:
The first piece of information is the metadata, which includes the wiki ID, URL, and the title of the article to which the paragraph belongs.
The second piece of information is a feature we recently added to Upstash Vector, which allows you to store unstructured textual data alongside your vector. We used this new data field to store the textual representation of paragraphs so that they can be displayed in the search results.
With these elements in place, for each query text submitted by the user, we automatically convert it to a vector embedding using Upstash Vector and perform an approximate nearest neighbor search against the query embedding.
Regarding the query results, we observed a few things related to the model we used and the approximate nearest neighbor (ANN) search algorithm.
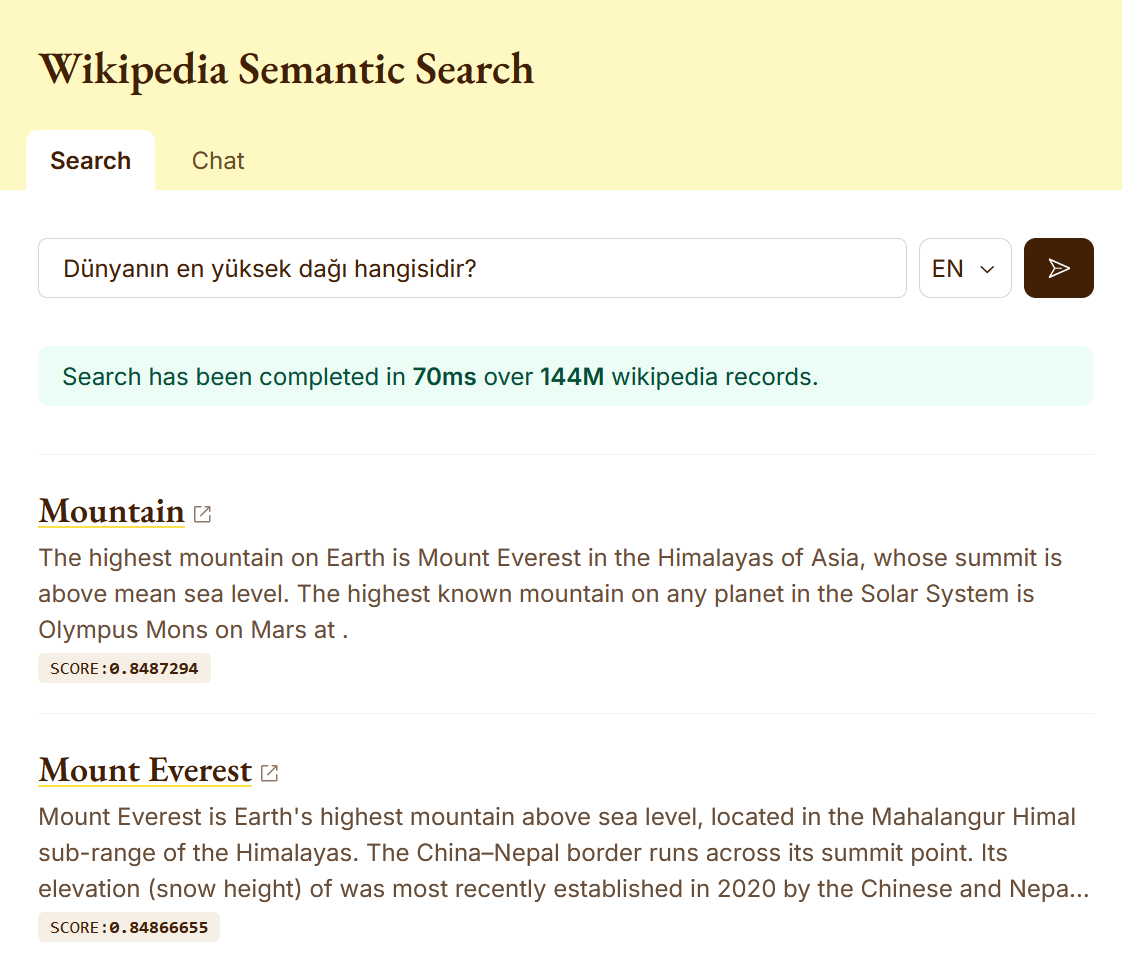
The first observation is that the BGE-M3 model is cross-lingual. It is impressive to see a query text written in Turkish,
such as Dünyanın en yüksek dağı hangisidir? (which translates to Which is the highest mountain in the world?),
can return accurate results when run against the English Wikipedia namespace.
The second observation is that the BGE-M3 model is cased, meaning that query results can differ significantly depending on whether the text is written in lowercase or uppercase, as opposed to using the correct casing. This behavior is expected from a model trained on such data, but it's important to consider this aspect when conducting queries.
The last observation relates to the algorithm used in the ANN search. We found that to achieve better results, it may be beneficial to overquery the index. For instance, if we need the top 5 results, it is more effective to request 50 results from the server and then select the top 5 on the client-side, rather than directly requesting the top 5 results from the server.
This approach is connected to the search heuristic used in JVector, the library implementing the DiskANN algorithm used in Upstash Vector. Broadly speaking, the algorithm maintains two heaps during queries: one for candidate results and one for the final results. The search begins by placing the entry point of the index graph into the candidates heap. The top item with the highest similarity score to the query text is popped from the candidates heap, added to the results heap while maintaining its size, and its neighbors are added to the candidates heap. This process continues until the top similarity score in the candidates heap is lower than the lowest similarity score in the results heap, at which point the search concludes, assuming the current results are sufficiently good.
As this is an approximate search, this heuristic is acceptable, but it may mean some high-quality results in the graph remain unexplored. This issue becomes more apparent with lower top-K values requested from the server, as the search loop ends more quickly, potentially before exploring parts of the index graph that might be more relevant to the query.
RAG Chat
Upstash RAG Chat is an SDK designed to build powerful RAG applications, allowing you to focus on the application itself without the hassle of integrating various tools.
The SDK supports using Upstash Vector as the knowledge base, storing chat histories in Upstash Redis, and rate limiting chat messages with Upstash, all with minimal code.
Since we already had the vector database ready for semantic search, integrating it into the RAG chat was straightforward.
We were able to use the existing index as is, since it was created with an embedding model.
For the LLM provider, we used meta-llama/Meta-Llama-3-8B-Instruct, also provided by Upstash through
QStash LLM APIs.
Lastly, we used Upstash Redis to store the chat sessions and seamlessly integrated all these tools with just a few lines of code.
You can check out source code of the project here.
Closing Words
It was great to index much of Wikipedia, from creating the embeddings to inserting them into Upstash Vector, and to see good query results even with large namespaces.
The features in Upstash Vector, such as automatic vector embeddings, namespaces, and the ability to store and retrieve both structured and unstructured data, made the process quite easy. It was also reassuring to see that it can handle large indexes without affecting query times or quality.
We had a lot of fun with this project and believe that Upstash Vector is well-suited for building scalable and reliable systems. If you have any feedback about the project or Upstash Vector, feel free to reach out. Let’s work together to make it even better!